Published at 2021-05-06 18:37
Author:zhixy
View:2252
SAM (sequence alignment format) 是一种专门用于储存序列比对信息的文件格式,BAM文件是SAM的二进制文件。
当测序生成的fastq文件比对到参考基因组后就会生成SAM文件或者BAM文件。
SAM文件包括头部注释和比对结果两部分,头部注释为''可选部分''。
头部注释位于比对结果之前,以“@”开头。比对结果有11列是固定的,其他多列可选。
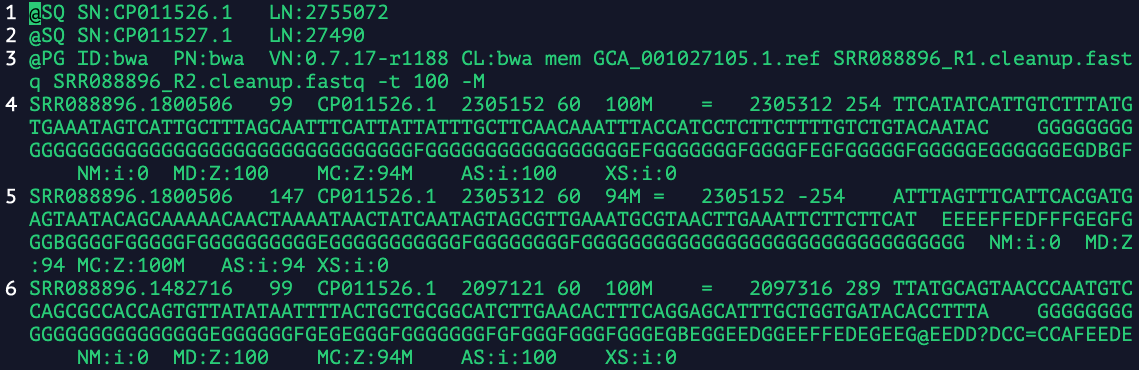
在上图的示例中,前三行为头部注释。
有时还会有 (推荐的规范):
@HD VN:1.0 SO:unsorted
VN是格式版本;SO表示比对排序的类型,有unkown (default),unsorted,queryname和coordinate几种。
从第四行开始为比对结果,自左向右,前11列为固定字段,分别为:
1:表示read有多个测序数据,一般理解为有双端测序数据,另一条没有过滤掉;2:表示read的多个片段都有比对结果,双端的read都能比对上;4:表示该read没有比对上;8:表示下一条read没有比对上;16:表示该read的反向比对上了;32:表示该read的下一条的反向没有比对上;64:表示样本中第一条片段;128:表示样本中最后一条片段;256:表示第二次比对;512:表示比对的质量不合格;1204:表示read是PCR或光学副本产生的;2048:表示辅助比对结果;*。0;*,该片段和下一个片段比对上同一个参考片段,用=;可选字段以TAG:TYPE:VALUE的形式提供额外的信息。
samtools是一个用于操作SAM和BAM文件的工具合集。BAM文件优点:BAM文件为二进制文件,占用的磁盘空间比SAM文本文件小;且基于BAM二进制文件的运算速度快。
功能:将SAM文件转换成BAM文件,以便于对BAM文件进行各种操作。
用法: samtools view [options]
默认情况下不加region,则是输出所有的regions。
头部注释,默认时不输出;-H 仅输出头部注释,无比对结果比对结果,而仅计数例子:
# samtools view -b -S abc.sam -o abc.bam
将SAM文件转换成BAM文件。
# samtools view -b -F 4 abc.bam > abc.F.bam
提取比对到参考序列上的比对结果。
# samtools view -b -F 12 abc.bam > abc.F12.bam
提取paired reads中两条reads都比对到参考序列上的比对结果,只需把两个48的值12作为过滤参数。
# samtools view -bf 4 abc.bam > abc.f.bam
提取没有比对到参考序列上的比对结果。
# samtools view abc.bam scaffold1 > scaffold1.sam
提取BAM文件中比对到scaffold1 (作为region名称) 上的比对结果,并保存到SAM文件格式。
# samtools view abc.bam scaffold1:30000-100000 > scaffold1_30k-100k.sam
提取scaffold1上能比对到30k到100k区域的比对结果。
功能:对BAM文件进行排序。
用法: samtools sort [-n][-m ] <in.bam> <out.prefix>
例子:
# samtools sort abc.bam abc.sort
对abc.bam进行排序,输出文件为abc.sort.bam。
功能:对BAM文件建立索引,并生成后缀为.bai的文件,用于快速的随机处理。很多情况下需要有bai文件的存在,特别是显示序列比对情况下,比如samtool的tview命令。
用法:samtools index <in.bam> [out.index]
例子:
# samtools index abc.sort.bam abc.sort.bam.bai
生成abc.sort.bam的索引文件abc.sort.bam.bai,输出文件名可省略。
功能:对fasta文件建立索引,并生成后缀为.fai的文件。该命令也能依据索引文件快速提取fasta文件中的某一条子序列。
用法:samtools faidx <in.bam> [ [...]]
例子:
# samtools faidx genome.fasta
# samtools faidx genome.fasta scaffold_1 > scaffold_1.fasta
从genome.fasta中提取名为scaffold_1的字序列。
功能:直观的显示出reads比对基因组的情况。
用法:samtools tview <aln.bam> [ref.fasta]
如给出参考基因组,会在第一排显示参考基因组的序列,否则,第一排全用N表示。显示界面下操作指令的使用说明,可按?键来查看。
功能:用于生成bcf文件,再使用bcftools进行SNP和Indel的分析。bcftools是samtool中附带的软件。
用法:samtools mpileup [-EBug][-C capQcoef] [-r reg][-f in.fa] [-l list][-M capMapQ] [-Q minBaseQ][-q minMapQ] in.bam [in2.bam]
例子:
# samtools mpileup -f genome.fasta abc.bam > abc.txt
mpileup不使用-u或-g参数时,则不生成二进制的bcf文件,而生成一个文本文件(输出到标准输出)。
结果包含6列:参考序列名;位置;参考碱基;比对上的reads数;比对情况;比对上的碱基的质量。
# samtools mpileup -g -S -D -f genome.fasta abc.bam > abc.bcf

